TRPO是英文单词Trust region policy optimization的简称,翻译成中文是信赖域策略优化。
从宏观意义上来讲,TRPO将统计玩到了一个新高度。在TRPO出来之前,大部分强化学习算法很难保证单调收敛,而TRPO却给出了一个单调的策略改善方法。所以,不管你从事什么行业,想用强化学习解决你的问题,TRPO是一个不错的选择。
策略梯度的缺点
上一节,我们已经讲了策略梯度的方法。当然策略梯度方法博大精深,上一讲只是给出一个入门的介绍,在策略梯度方法中还有很多有意思的课题,比如相容函数法,自然梯度法等等。但Shulman在博士论文中已证明,这些方法其实都是TRPO弱化的特例,说这些是再次强调TRPO的强大之处。
我们知道,根据策略梯度方法,参数更新方程式为:
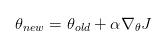
策略梯度算法的硬伤就在更新步长 ,当步长不合适时,更新的参数所对应的策略是一个更不好的策略,当利用这个更不好的策略进行采样学习时,再次更新的参数会更差,因此很容易导致越学越差,最后崩溃。所以,合适的步长对于强化学习非常关键。
什么叫合适的步长?
所谓合适的步长是指当策略更新后,回报函数的值不能更差。如何选择这个步长?或者说,如何找到新的策略使得新的回报函数的值单调增,或单调不减。这是TRPO要解决的问题。
TRPO是找到新的策略,使得回报函数单调不减,一个自然地想法是能不能将新的策略所对应的回报函数分解成旧的策略所对应的回报函数+其他项。只要新的策略所对应的其他项大于等于零,那么新的策略就能保证回报函数单调不减。其实是存在这样的等式,这个等式是2002年Sham Kakade提出来的。TRPO的起点便是这样一个等式:

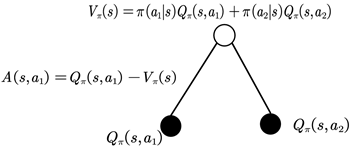
值函数可以理解为在该状态下所有可能动作所对应的动作值函数乘以采取该动作的概率的和。更通俗的讲,值函数是该状态下所有动作值函数关于动作概率的平均值。而动作值函数是单个动作所对应的值函数,能评价当前动作值函数相对于平均值的大小。所以,这里的优势指的是动作值函数相比于当前状态的值函数的优势。如果优势函数大于零,则说明该动作比平均动作好,如果优势函数小于零,则说明当前动作还不如平均动作好。



This equation implies that any policy updateπ→π̃that has a nonnegative expected advantage ateverystates, i.e.,aπ̃(a|s)Aπ(s,a)≥0, is guaranteed to increase the policy performanceη, or leave it constant in the case that the expected advantage is zero everywhere. This im- plies the classic result that the update performed by ex- act policy iteration, which uses the deterministic policy π̃(s) = argmaxaAπ(s,a), improves the policy if there is at least one state-action pair with a positive advantage value and nonzero state visitation probability, otherwise the algorithm has converged to the optimal policy. However, in the approximate setting, it will typically be unavoidable, due to estimation and approximation error, that there will be some statessfor which the expected advantage is negative,

Monotonic Improvement Guarantee for General Stochastic Policies