1.传统上的学习方法用来如何根据高维的输入数据(视觉,语音)控制智能体依赖于手工挑选的特征表示以及线性的value function 或者policy representation。
深度学习强大的特征学习能力应用到强化学习领域是大势所趋。
然而,强化学习领域的特性对深度学习的能力发起了挑战:
1.深度学习的训练方法仍依赖大量的带label的数据集。然而。强化学习面对的是数字量reward信号,稀疏,噪音,延时。
特别是延时reward使得action 和reward 之间无法建立联系,无法确认到底是哪个action对此reward有贡献。
对于深度学习的带标签的数据集来说,其特征及label的对于关系是显而易见的。
2.大部分深度学习算法假设数据采样是独立同分布的(idd),然而强化学习面对的状态序列确实强相关的因果关系,
而且当强化学习得到的策略改变时,同一state映射到的action也会不同,
这对于假设特征于标签有一一对应关系的深度学习方法来说是个病态的问题。
本篇论文提出一种cnn,利用Qlearning及SGD训练权重,最终能够从图像数据学习到控制策略。
1.为了解决数据相关性的问题,提出经验回放机制(experience replay mechanism),随机从缓存数据中采样,时数据分布更加平滑。
Atari 2600 is a challenging RL testbed that presents agents with a high dimensional visual input (210x160 RGB video at 60Hz) and a diverse and interesting set of tasks that were designed to be difficult for humans players.
本论文设计一种神经网络模型,完全从原始的图像数据开始学习,毫无任何人工特征或先验知识,从游戏获取的reward得分会提供训练的signal。
2.backgroung
agent与环境交互过程建模:a sequence of actions, observations and rewards.
每一步,agent 从合法的actions 中选取一个action。每一步的action 传入 环境,改变环境的内部状态。
然而环境可能是随机的,并且环境的内部状态是不可知的,agent只能通过传感器观察到observation,并且获取得分reward。
注意:当前的得分与先前的一系列actions有关,而且当前的action获得的reward可能发生在数千步之后。
agent无法根据当前的观察完全的理解环境状态,因此考虑用一系列的actions, observations为当前状态建模。
st=x1;a1;x2;:::;at
并根据这个序列学习agent的控制策略。
由于所有的游戏都是一个有限步数的回合,可以引入Markov decision process (MDP) ,把每个每个完整的序列作为当前状态,应用强化学习方法。
智能体的目的在于通过跟环境交互,通过观察状态选取能够最大化未来回报的行动。
未来 回报定义为未来每一步乘以折扣系数,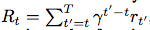
最优 的动作价值函数:依据某种策略能够最大化其未来回报的期待 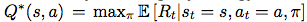
最优动作价值函数服从Bellman equation
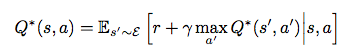
假设 最优q函数已知下一个状态s'所有动作的价值,那么最优策略将选择能够最大化 的动作。
的动作。
许多 强化学习背后的做法是通过迭代Bellman equation更新,来估计价值函数。并且该迭代算法的收敛可以得到证明,
为了提高泛化能力,采用函数拟合的方式来逼近价值函数。通常采用神经网络作为非线性拟合器。
通过 最小化一个动作序列的loss训练神经网络
目标 值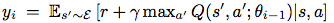 ,取决于神经网络的权重,不同于监督学习。
,取决于神经网络的权重,不同于监督学习。
这个model-free的方法,通过对仿真器采样,避免的对环境模型的估计。
off-policy:following a behaviour distribution that ensures adequate exploration of the state space. In practice, the behaviour distribution is often se- lected by an ε-greedy strategy
相关基础工作:
TD-gammon:This architec- ture updates the parameters of a network that estimates the value function, directly from on-policy samples of experience,st, at, rt, st+1, at+1, drawn from the algorithm’s interactions with the envi- ronment (or by self-play, in the case of backgammon).
改进:
- 经验回放:将每一步的状态动作和回报存入数据库replay memory中,随机从中选出一个batch进行SGD更新权重,利用ε-greedy strategy选取动作。
- 优点:提高数据利用率,随机选择数据降低数据相关性,避免on-policy时采样数据被策略决定下的不均衡情况,off-policy可以时数据更平滑。避免陷入局部最小值。
Note that when learning by experience replay, it is necessary to learn off-policy (because our current parameters are different to those used to generate the sample), which motivates the choice of Q-learning.

给定转移 <s, a, r, s'>,Q-table 更新规则变动如下:
- 对当前的状态 s 执行前向传播,获得对所有行动的预测 Q-value,选取取得最大Q-value 的 at=argmax Q(s,a)
- 将at传入模拟器,获取rt,s‘
- 对下一状态 s' 执行前向传播,计算网络输出最大操作:max_{a'} Q(s', a')
- 设置行动的 Q-value(st,at) 目标值为 rt + γ_max\{a'} Q(s', a')。或者rt,终结状态时。
- 使用反向传播算法更新权重