Human-level control through deep reinforcement learning
Here we use recent advances in training deep neural networks to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning.
The goal of the agent is to select actions in a fashion that maximizes cumulative future reward. More formally, we use a deep convolutional neural network to approximate the optimal action-value function 
神经网络作为非线性函数逼近器会发生不稳定甚至无法收敛的问题,原因在于:
- 观察序列数据的相关性
- 采样的数据分布受到策略权重更新的影响较大
- target q value 根据网络权重计算得出,也容易受到权重更新的影响。
改进:
- 记忆回放,随机采样,去除数据相关性,提高分布平滑度
- 周期性更新target network
To perform experience replay we store the agent’s experienceset (st,at,rt,st11) at each time-steptin a data set Dt{e1,...,et}.
During learning, we apply Q-learning updates, on samples (or minibatches) of experience (s,a,r,s’),U(D), drawn uniformly at random from the pool of stored samples. The Q-learning update at iterationiuses the following loss function:
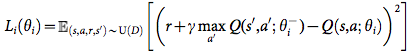
in whichcis the discount factor determining the agent’s horizon,hi are the parameters of the Q-network at iteration i and h{i are the network parameters used to compute the target at iteration i. The target net- work parameters are only updated with the Q-network parameters (hi) every C steps and are held fixed between individual updates (see Methods).
Detail:

- As the scale of scores varies greatly from game to game, we clipped all posi- tive rewards at 1 and all negative rewards at21, leaving 0 rewards unchanged. Clipping the rewards in this manner limits the scale of the error derivatives and makes it easier to use the same learning rate across multiple games.Because the absolute value loss functionjxjhas a derivative of21 for all negative values ofxand a derivative of 1 for all positive values ofx, clipping the squared error to be between21 and 1 cor- responds to using an absolute value loss function for errors outside of the (21,1) interval. This form of error clipping further improved the stability of the algorithm.
- in these experiments, we used the RMSProp (see http://www.cs.toronto.edu/,tijmen/csc321/slides/lecture_slides_lec6.pdf ) algorithm with minibatches of size 32. The behaviour policy during training wase-greedy witheannealed linearly from 1.0 to 0.1 over the first million frames, and fixed at 0.1 thereafter. We trained for a total of 50 million frames (that is, around 38 days of game experience in total) and used a replay memory of 1 million most recent frames.
- Following previous approaches to playing Atari 2600 games, we also use a simple frame-skipping technique15. More precisely, the agent sees and selects actions on every kth frame instead of every frame, and its last action is repeated on skipped frames. Because running the emulator forward for one step requires much less computation than having the agent select an action.
- use a separate network for generating the targetsyjin the Q-learning update. More precisely, everyCupdates we clone the networkQto obtain a target networkQ^and useQ^for generating the Q-learning targetsyjfor the followingCupdates toQ. This modification makes the algorithm more stable compared to standard online Q-learning, where an update that increasesQ(st,at) often also increasesQ(st11,a) for allaand hence also increases the targetyj, possibly leading to oscillations or divergence of the policy. Generating the targets using an older set of parameters adds a delay between the time an update toQis made and the time the update affects the targetsyj, making divergence or oscillations much more unlikely.
DeepMind 其实还使用了很多的技巧来让系统工作得更好——如 target network、error clipping、reward clipping 等等
该算法最为有趣的一点就是它可以学习任何东西。你仔细想想——由于我们的 Q-function 是随机初始化的,刚开始给出的结果就完全是垃圾。然后我们就用这样的垃圾(下个状态的最高 Q-value)作为网络的目标,仅仅会偶然地引入微小的收益。这听起来非常疯狂,为什么它能够学习任何有意义的东西呢?然而,它确实如此神奇。
Final notes
Many improvements to deep Q-learning have been proposed since its first introduction – Double Q-learning, Prioritized Experience Replay, Dueling Network Architecture and extension to continuous action space to name a few. For latest advancements check out the NIPS 2015 deep reinforcement learning workshop and ICLR 2016 (search for “reinforcement” in title). But beware, that deep Q-learning has been patented by Google.
It is often said, that artificial intelligence is something we haven’t figured out yet. Once we know how it works, it doesn’t seem intelligent any more. But deep Q-networks still continue to amaze me. Watching them figure out a new game is like observing an animal in the wild – a rewarding experience by itself.